Parallel Vs Concurrent Programming
The birth of thread comes from the concept/troubles of Parallel and Concurrent programming. I find myself confused many times and have used these interchangeably.
Concurrent Programming : Refers to environment when tasks occur in (any) order. You can switch between tasks using algorithm such as Round-Robin to execute few or more tasks simultaneously.
Parallel Programming : Refers to environment when we execute concurrent processes simultaneously on different processors/cores.
Thus, parallel programming is concurrent, but not all concurrent programming is parallel.
Process vs Thread
Now that we know, we need to have concurrency and parallelism in our system. The next question needs to be asked is how do we achieve this.
Before going further, I am assuming you are aware of difference between Process and threads in Operating System. To say in brief,
Process : An independent program in execution. Each process will have its own resources, memory space and system isolation.
Thread : A lightweight unit of execution within process that shares same memory space and resources as other threads of the same process.
Program -> Process -> Thread
| Process | Thread | |
| Address Space | Every process has seperate address space. | Threads within same process share address space. |
| Crash Resiliance | If one process crashes, the other remains unaffected. | Depending on way we create, crash in thread can affect other threads . |
| Performance | Heavy-weight, suitable for systems that has significant resources. | Suitable for high-performance applications due to lower overhead. |
| When to use | When you want to leverage multi-core system with no shared-memory requirement. | Ideal for splitting tasks into smaller, parallelizable units that requires memory/ data sharing. |
MultiProcess vs MultiThread
The next step for us is to understand the tools we have in our arsenal to use. The classic Unix system extensively leverages Multiprocess paradigm.
Lets write a C program that calculates the volume of cube and prints it using fork system call to make it Multiprocess programming.
/
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
int volume; // Shared variable to store the volume
void calculate_volume(int side) {
volume = side * side * side;
printf("Calculated Volume (Process %d): %d\n", getpid(), volume);
}
void print_volume() {
printf("Printed Volume (Process %d): %d\n", getpid(), volume);
}
int main() {
int side = 5; // Example side length of the cube
pid_t pid = fork();
if (pid == 0) {
// Child process: Calculate the volume
calculate_volume(side);
// exit(0); // Removing exit
} else if (pid > 0) {
// Parent process: Wait for the child to finish, then print the volume
wait(NULL);
print_volume();
} else {
perror("Fork failed");
}
return 0;
}
Parent Process Waiting for Child to finish
Child Process calculating Volume
Calculated Volume (Process 5445): 125
Printed Volume (Process 5444): 0
What do we see here:
Even after making volume a global variable, the printed volume comes 0. This proves fork() call does not have any memory sharing facility here. Both parent and child, have their own memory space and complete segregation of resources.
There is a predefined relationship here – parent and child.
With exit(0), child process exits, parent process will keep on going.
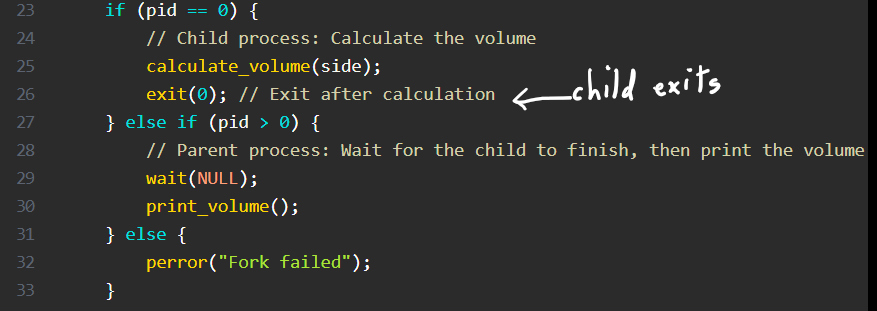
Going again, if you remove exit(0)and comment out wait(NULL) call from parent-else block,your child process (it means pid ==0), you will keep on going until the main exits.
On the other hand, you would notice, the else condition (pid >0) ,enlists wait() call in the block. This means parent process only can call wait on child process and not the other way around.
Why don't you try to removing wait(NULL) call, exit(0) and run the code?
What happens we add printf just before return? How many times will it get printed?
If you miss/ do not call wait() in this section, parent process will exit making child zombie process.
Lets write the same program using multi-threading approach.
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
pthread_mutex_t mutex;
int volume; // Shared variable to store the volume
void* calculate_volume(void* arg) {
int side = *(int*)arg;
pthread_mutex_lock(&mutex);
volume = side * side * side;
printf("Calculated Volume (Thread %ld): %d\n", pthread_self(), volume);
pthread_mutex_unlock(&mutex);
return NULL;
}
void* print_volume(void* arg) {
pthread_mutex_lock(&mutex);
printf("Printed Volume (Thread %ld): %d\n", pthread_self(), volume);
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t thread1, thread2;
int side = 5; // Example side length of the cube
pthread_mutex_init(&mutex, NULL);
// Create thread for volume calculation
pthread_create(&thread1, NULL, calculate_volume, &side);
pthread_join(thread1, NULL); // Ensure calculation completes before proceeding
// Create thread for printing the volume
pthread_create(&thread2, NULL, print_volume, NULL);
pthread_join(thread2, NULL);
pthread_mutex_destroy(&mutex);
return 0;
}
Calculated Volume (Thread 140598715426560): 125
Printed Volume (Thread 140598715426560): 125
We are successfully able to calculate and print volume in two separate threads. This is because threads share memory within same process, making global variable sharable.
We also notice, pthread_join is being called for both the threads. Unlike, fork() call, there is no hierarchy/ special relation between the threads.
It is also worth noticing, in multi-threaded programming, we can clearly define the starting point of a thread. But in fork() call, both child and parent starts execution from line next to fork() call.